So, over the past two months, I was assigned to create use-case diagrams. I found a handy tool for this purpose i.e., draw.io . I never touched this type of diagram in my entire professional career. I learnt how to draw ones when I was in college, sure. But spending most of my time to date as a programmer or data engineer, I never got the chance to actually create one. It was clear that when I got this assignment, I was spending a substantial amount of time just figuring out how to include a dashed connecter (typically for representing "include" or "extend"). The funny thing is I could not find any clue of how to do this in their blog . So, here's how. Step 0: Initiation Suppose we have two cases: case 1 and case 2 ( I know it was a genuine mistake to name the two cases as use case 1 and use case 2 as shown below. Heck, I'm too lazy to update the pictures, so from now on we will assume the name of the cases are case 1 and case 2, respectively). We want to...
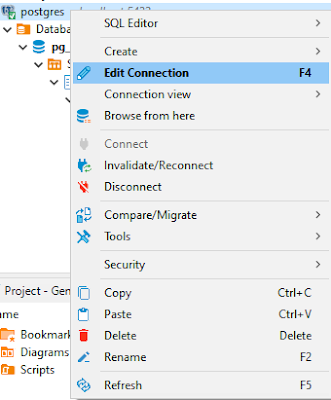
Recently, I encountered an error, saying: "Error: database already exists" This error came up when I thought the database I was trying to search was missing. So, I tried to create another new database with the same name. It's quite strange as on the Database Navigator pane at Dbeaver, the database remains hidden somewhere and the annoying this is we cannot create a new one. So, as always, I looked up Stackoverflow and find the workaround was rather simple. Right-click on the connection and fire Edit Connection Head to the PostgreSQL tab and make sure to tick the Show all databases on Click OK Problem solved! Credit to: oluwasegun for his response on the following StackOverflow thread: https://stackoverflow.com/questions/61979762/dbeaver-postgresql-error-database-already-exists-but-i-cant-find-it
I'm new to this visualisation area, let alone visualisation in Power BI. Despite lacking of practical experience in this area, I managed to get the opportunity to be an instructor in a distance learning where I was assigned to share a how-to in generating reports and dashboards using Power BI. The following report is based on the famous Sakila dataset . Any feedback is welcomed! 😃
Comments
Post a Comment